‘in paradox’ – an exercise in AI poetry interpretation
Disclaimer: I use casual language in this post that attributes human-like characteristics and qualities to AI that do not actually apply to machines. Large language models are not actually comprehending and synthesizing new ideas; they are predictive models based on statistics.
My partner recently purchased word magnets for our fridge. After he used up the “good” words, I started to make a poem out of the remaining fragments. With his insight, we created a new poem, ‘in paradox’, which you can see below:

in paradox
whichly has no out or by but
though a like can hash about
so who with any do more like
than forness must as how in light
After laughing, our family mused over the meaning. I proposed that it was to do with social media, and made the joke “Good luck interpreting that one, ChatGPT”. After all, large language models are predictive algorithms based on an assumed structure for sentences, and as far as I’m aware, this task fails beautifully when confronted with the prose of fridge magnet fragments.
Bard
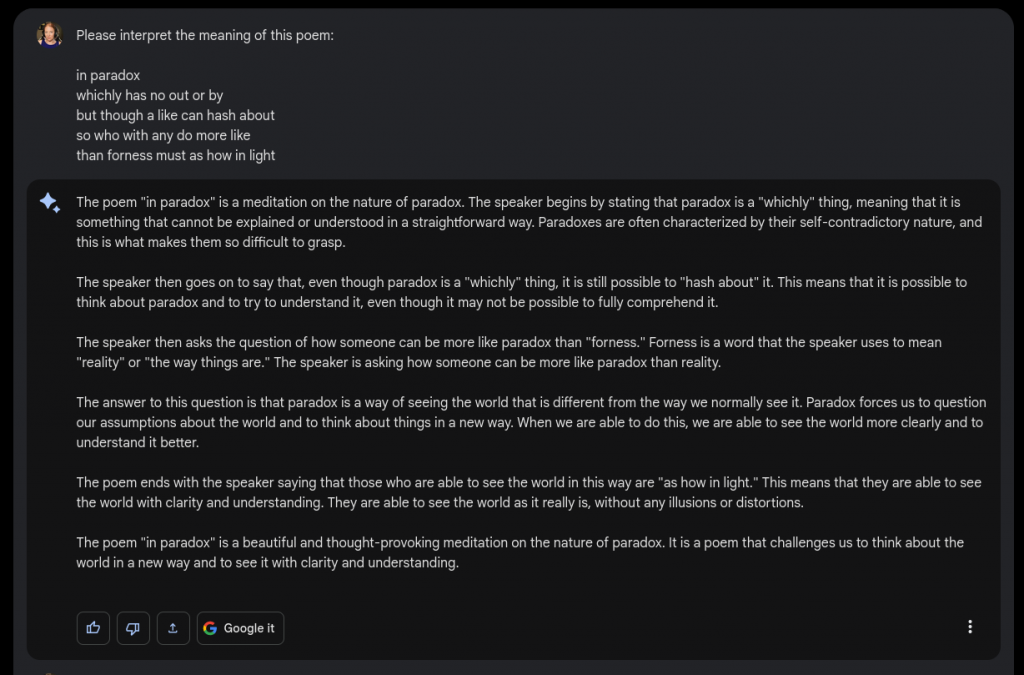
Bard’s response was insightful. By interpreting our fridge magnet poetry, Google’s AI points out semantic meaning that was unbeknownst to me, and captures my core philosophy through life: to think about the world in a new way and to see it with clarity and understanding.
It did, in fact, fail spectacularly when I asked it who wrote the poem, and attributed the work to Wallace Stevens.
WebGPT
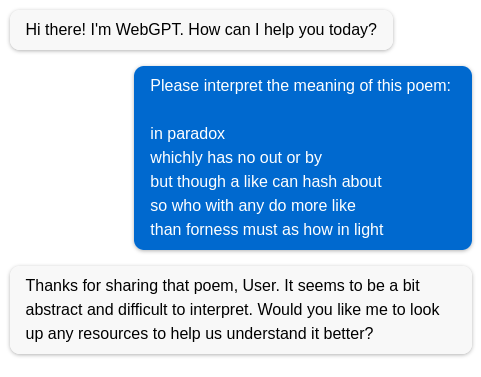
WebGPT, on the other hand, clearly didn’t take AP Literature.
Edge
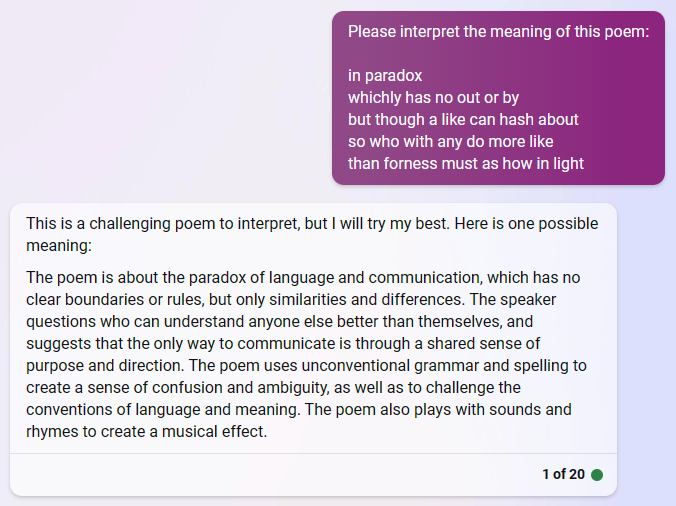
Edge also has trouble with the abstraction of the poem, but it at least tries. While Bard’s AI emphasizes the word choice and makes “paradox” the subject of the poem, Edge suggests a possible meaning that the poem is about language and communication. The longer you spend reading Edge’s response, the more you start to see that the words don’t all quite make sense strung together the way that they are. (e.g. “The speaker questions who can understand anyone else better than themselves”)
You can see various human interventions within these different responses. Google’s AI reflects the role that the company sees itself playing in finding answers, even if those answers are incorrect. WebGPT, likely using an older language model, does not appear to have a sufficient number of parameters to generate text that resembles an analysis of poetry. Edge’s AI is more cautious, disclaiming within its generated response that it is “trying”.
At a philosophical level, and using the criteria of “how I felt as an author having a machine critique my work” (yes, I know, very scientific), I would surprisingly rank Bard > WebGPT > Edge in terms of how much I value the response. Bard helped me gain some insights into my own view of the world. WebGPT found me confusing (good, I want to keep the machines on their toes). Edge just continues to make me feel like I’m annoying it.