TIL: The One-Model-Many-Models Paradigm
Continuing on in my read through of the CRFM’s “On the Opportunities and Risks of Foundation Models” paper, today I’m noting an interesting concept that relates to AI model interpretability. Interpretability is one of the major issues with the largest of our AI computing models (and a key principle in understanding how they work + the impact that their output might have), and it’s further exacerbated in foundation models because these models are often used to train more specialized downstream models towards task-specific capabilities.
An interpretable system is one where it is possible to have clarity around the expected behaviors of a model. Historically, the concept of an “interpreter” in computer science is used to describe a program that can convert a program into machine-readable execution code, and up until now, the programs have been deterministic – you wouldn’t have unexplainable functions running that the interpreter couldn’t understand.
With foundation models, the new way of describing the behavior of models is “emergent”, although I personally find this term to be a bit overreaching. What it means is that the output and behavior of an AI model is unpredictable and inconsistent (I’ll admit those aren’t the most charitable ways of framing it, but I mean it without judgement) and subsequently, much harder to interpret and understand. As an example, you can take a given AI application that uses a particular model, and ask it a question ten times, and get ten different answers. Today, it’s almost impossible (at least as far as I’m aware) to understand why a given model and application would come to the various conclusions that it does that would result in those answers. Then again, depending on the question, it might be argued that humans also have inconsistent and unpredictable answers to the same questions, too.
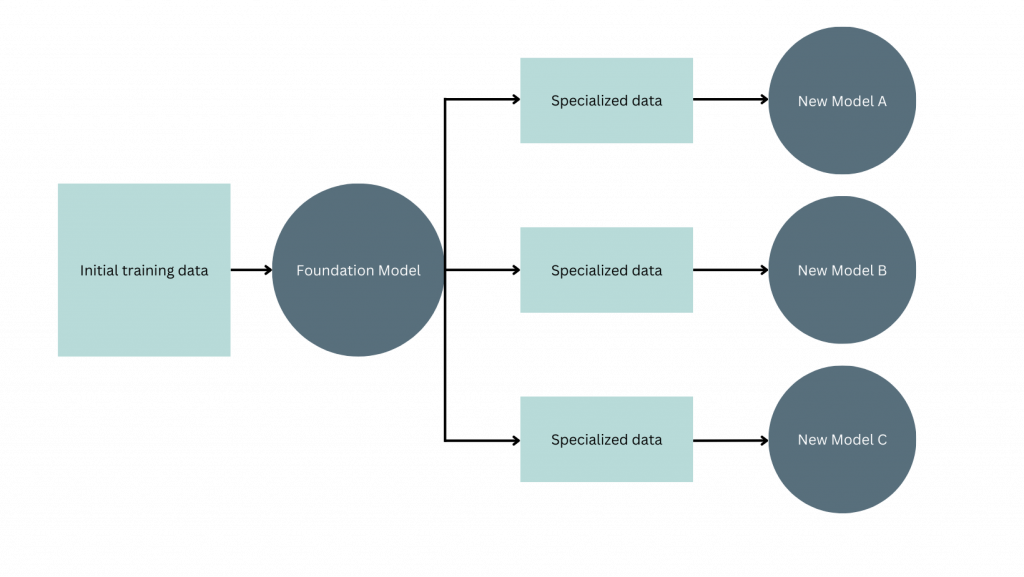
Because foundation models are used to build many other models that are trained to new, more specific tasks, it can be hard to evaluate models consistently. A foundation model may be seen as largely “incomplete” without further fine-tuning and training, but the process of fine-tuning and adding in additional data to the training set can fundamentally change the behavior of the system.
As far as I can understand, the one-model-many-models paradigm attempts to study interpretability of foundation models by looking for similarities and differences across the foundation model and its downstream models to try and understand which behaviors were likely emergent from the foundation model itself, and which come from the derivative models. It essentially points out that we can’t evaluate a foundation model’s behavior in isolation, but instead need to consider it within the context of how it’s ultimately used.
Perhaps uncharitably, I can’t help but draw comparisons to colonization and religious missionary work. Foundation models – currently limited to those who can afford massive compute resources, access to petabytes of private data, and paying massive deep learning engineer salaries – are inherently privileged, and have massive influence over the ecosystem as a whole. Rather than investing in infrastructures for distributed, collaborative models built on shared value exchange and equitable access and digital autonomy, the builders of foundation models (Musk and Thiel-backed OpenAI, Meta, the government of Abu Dhabi), naturally continue to exercise their desire for power and social control over humanity.
But it’s the robots we’re supposed to fear, amiright?