TIL: Adding a Not-Yet-Landed Patch into my Local Firefox Build
I wrote a recent TIL about building Firefox from source, and it was in service of landing this particular patch. Warning – there be demons ahead.
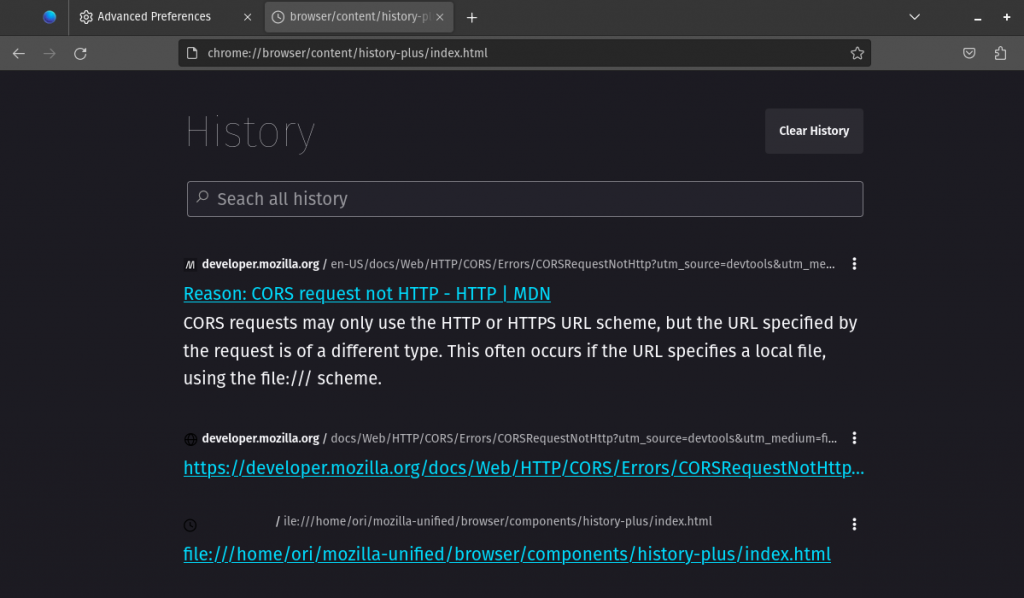
Local Firefox is built… now what?
I wanted to build Firefox from source in order to implement the changes found in the patch stack linked above. That’s the beauty of open source – I was able to be sent a patch that someone wrote last summer, and even though it hasn’t been made production-ready and merged, I can start working with it immediately.
In theory, I could have used mercurial to cherry-pick these commits into my local version. I didn’t do that. Instead, I went through the 8-stack and started with the first dependency, copied the code down into my repo using a combination of vim and VSCodium (a version of VS Code that has the Microsoft bits stripped out). I re-built Firefox after each patch, to reduce the surface area for errors along the way.
When I finally built the last of the eight patches, I went to the local URL chrome://browser/content/history-plus/index.html as instructed in the Phabricator link, and… nothing.
CORS, Of Course
When I popped open the developer tools, I noticed that it was the dreaded CORS error. Now, I can sometimes work my way through these on a good day, when I’m not working with a home-grown browser stack, but today I had No Patience. YOLO.
I changed some of the WARNING YOU MIGHT BREAK THINGS settings in about:config, specifically:
security.fileuri.strict_origin_policy(to false)security.mixed_content.block_active_content(to false)security.mixed_content.block_display_content(to true)
I’m reasonably confident in my abilities and sandbox that I didn’t cause permanent harm for this particular use case, but if you’re a friendly and want to explain to me why I’m wrong, please do.
Wait, so what’s it actually doing?
The full Phabricator stack that I linked to above is doing a few different things:
- It’s enabling FTS5 for SQLite, which allows text search
- It’s creating a new actor to cache content from pages you visit, then storing this cache, compressed, into the SQLite database that is built-in to the browser
- It adds a script to scrape and fill out the history that gets cached (note: I’m not sure if the Marionette script is only required for testing, or if it’s necessary to have the functionality work. I included it)
- It adds a component to show the cached results to the
history-plus/index.htmlpage.
Now what?
Now, the shiny screenshot you see above appears when I navigate to the index.html page of the history-plus component that I’ve added. When I visit new pages, they’re showing up here. If the page has proper metadata, there is some descriptive text that shows up (hence the presumed choice of “history-plus” – it’s your history, plus context from the page).
There are a few things on my now-growing to-do list:
- Build this on my Mac
- Figure out how to fix my own site post metadata so that the summarized text shows up
- Poke around with the script to try to scrape more of the webpage content
- Find a way to interface with the SQLite DB on my local computer to ingest it in privateGPT.
Happy Monday!