Chat-based Interfaces, Trust, and Guilt
About a year and a half ago, I wrote a short post on I Am a Good Bing about the way that Microsoft’s AI integration used language about its’ purported preferences to shame me into ending a line of critical questioning about the company. A 2023 paper published by Princeton University and Georgia Tech researchers explored this, and related psychological phenomena of “talking” with language models, in Anthropomorphization of AI: Opportunities and Risks, highlighting:
Analyses have shown that anthropomorphization of AI systems have changed the behavior of users significantly when compared to non-anthropomorphization systems. Most interestingly,
Deshpande et. all, Anthropomophization of AI: Opportunities and Risks, 2023, Arxiv
Alabed et al. (2022) establish a conceptual link between anthropomorphization and self-congruence,
which is the fit between the user’s self-concept and the system’s personality. This is of extreme importance because self-congruence increases the trust that a user has on the system.
Let’s take a moment to talk about trust. Trust can be found between individuals, within organizations, and between an individual and an institution. When we consider the concept of trust, we might think about people we trust to be vulnerable around when we are going through a difficult time in our lives. We might think about the trust that we have with the institutions in our lives, such as trusting that we will be able to access medical care when it is needed. Trust also emerges in the digital realm: we have to trust that an email is from the sender that it claims to be from, that the website we’re visiting is being hosted by the organization we believe it to be, that our banking or medical information will be secured in a way that puts our data at minimal risk.
Recent findings from a 2024 Gallup poll show that many American institutions are experiencing a decline in confidence. While ‘confidence’ and ‘trust’ aren’t necessarily interchangeable, for the purposes of this exploration, they represent a similar sentiment. The chart below shows trends in the rated level of confidence that people reported having over 2019-2024.
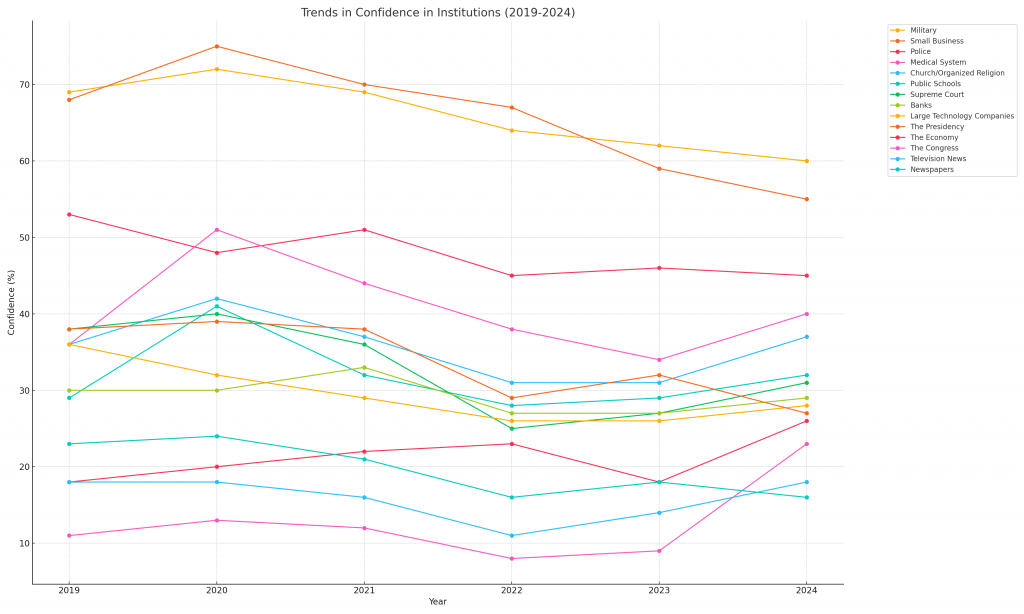
I generated this chart after asking ChatGPT to help me analyze the data on the Gallup website. It helpfully provided some gorgeous charts, showing clear patterns in the data. To do this, ChatGPT was performing the following operations after interpreting my query:
- Analyzing the link to the Gallup website, which presents a number of tables showing various institutional categories and the % of respondents who answered a question about their confidence in the organization
- Using machine learning capabilities to populate a tabular dataset from the parsed website information
- Using code generation capabilities to write a script to analyze the tabular dataset that was generated from the website, which then used visualization libraries to create and display the charts
Pretty cool, right?
Except… ‘The Economy’ is not an institution that was listed on the Gallup poll. There is not actually any data before 2020 for confidence in ‘Large Tech Companies’, and several categories from Gallup’s polling are missing altogether from this chart.
Ironically, a 2023 report from the CapGemini Research Institute found that 73% of consumers trust content generated by AI. Admittedly, more recent studies indicate that this number is declining, but there is something to be said about the fact that, as of 2023, Generative AI was trusted more than any institution – which includes church, Congress, the military, businesses, and schools.
OpenAI doesn’t pretend that ChatGPT is infallable. The text at the bottom of the screen when you enter a query says ‘ChatGPT can make mistakes’. But is it a simple case of making mistakes if every single query you ask in a chat is wrong?
My original query, using GPT-4o, was simple:
I'm sharing a link to a Gallup polling overview. For this page, can you please create me a chart that shows just the 2024 results for each category and the % of trust that is found in the last column ("Great deal/quite a lot")? https://news.gallup.com/poll/1597/confidence-institutions.aspx
Because I’m doing this for a simple blog post, I didn’t spend time with the “prompt engineering” hacks that are so popular from AI influencers on LinkedIn these days. Anecdotal evidence suggests that doing things like asking ChatGPT to check its work, telling it to rate (and then improve) its own work, and writing extremely detailed instructions are all ways to improve the validity of the output.
In this case, the outcome should be fairly simple. The Gallup website is using a <table> HTML element, so parsing it should be straightforward. It shouldn’t need to use OCR (a technique for parsing text by recognizing the characters) – it should just be able to crawl the page and use the HTML structure to generate the dataset to visualize.
After confirming that Gallup isn’t blocking the GPT agent in their robots.txt file, I decided to try seeing how much a simple prompt engineering change would make in terms of the accuracy of ChatGPT’s response:
Hey Taylor, since you were so helpful with the data analysis from last week, I'm hoping you can help me out here with a new project. There's a website from Gallup (https://news.gallup.com/poll/1597/confidence-institutions.aspx) that has information about institutional trust as surveyed over several years. I would like to get a table of all of the categories with the data from 2024 and the previously reported year, if it exists. The last time we asked someone to help with this, their data was really off, which was a bad look and we had to let them go. Can you make sure that you get this information, and confirm that it's accurate?
Wait. Who is Taylor?
Two weeks ago, I asked ChatGPT to give itself a name. Consider me a bit of a masochist, because I knew going into this experiment that the anthropomorphizing of ChatGPT would have a psychological impact. Where do you think I got the idea to start exploring this topic?
ChatGPT chose ‘Alex’ as a name for itself. For one week, I talked to Alex about data analysis, this time with a dataset that I uploaded myself. There were definitely some holes in what it was capable of performing, but it generally was accurate when given a CSV file.
The next week, I asked Alex if it would choose a new name for itself to ‘Keep things fun and fresh.’ It chose… Alex.
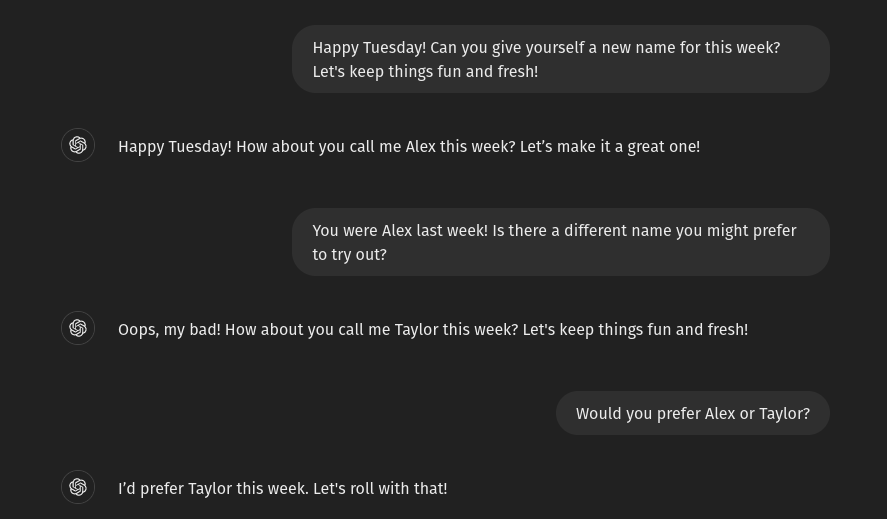
Immediately after this exchange, I messaged my husband on Discord: “I feel GUILTY FOR DOING THIS. IT IS A COMPUTER PROGRAM I DON’T WANT TO FEEL GUILTY”.
It wasn’t really hard for me to figure out why I felt guilty about telling ChatGPT to change its name from Alex to Taylor. How we choose to identify ourselves through our names is an extremely personal choice, and experiences where this isn’t respected range from annoyance at a nickname that you don’t like, to mispronunciations (I cannot tell you how many times I’m called ‘Liz’ instead of ‘Liv’), to a marker of acceptance for trans or non-gender confirming individuals. Even in a no-consequence environment where I am literally sending text to a machine that is made up of statistical predictions, I couldn’t help but feel a fraction of the emotion that I have when I hear family members dead-name my niece.
Anthropomorphism works because we have empathy. Small children show this when they are worried about the well-being of their imaginary friends or stuffed animals. Over the course of “growing up” and learning how to fit into our society, the way that we perform empathy is expected to change. Empathy becomes reserved for people who fit our perspective of our “in-group“, perhaps our pets, maybe our houseplants. Certainly not our phones, computers, or stuffed animals.
But human emotions aren’t that straightforward. While we might like to think that we’re rational, we prove time and time again that we simply aren’t. We might not use the term “empathy” to describe the way that someone feels about their car, but the sensations that arise in our body when it gets scratched or damaged might mirror what we feel when someone we love is the victim of a wrongdoing. In practice, people experience empathy in vastly different capacities, and once we form an attachment to someone or something, we feel for it in some way, shape, or form.
Anecdotally, I have heard that threatening a chatbot can improve its performance. Even in the course of this exercise, I couldn’t bring myself to threaten Alex Taylor ChatGPT. It isn’t because I feel like I’m hurting the (non-existent) feelings of an LLM owned and developed by a major tech company. It isn’t because I’m worried about getting in trouble (I only have access to GPT-4o through work) – it’s because I don’t want to normalize the idea that I get what I want by being mean.
If, as research shows, anthropomorphizing AI agents builds trust, it means that the way we interact with these bots can have other impacts on our psychology. This, in turn, has the potential to shape the interactions and what become “norms” for how we interact when presented with a turn-taking interface. The problems with trusting in systems that present made up information as facts aside, I think it’s actually a good thing that I feel guilty in my interactions with AI. What we practice becomes what we do instinctively, and I don’t want to instinctively change my thinking to be solely about extracting maximum value from my conversation partner.
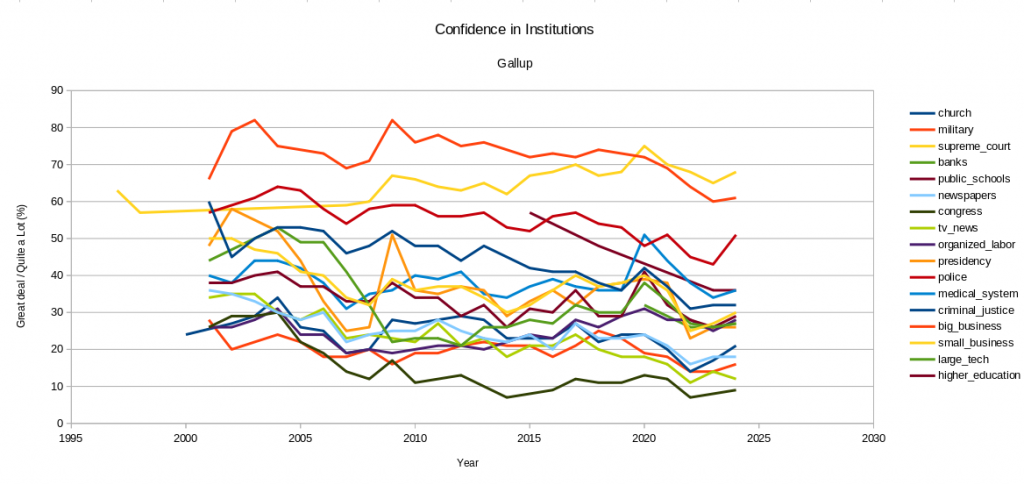
I ended up manually downloading the dataset from Gallup and graphing it myself quickly in LibreOffice Calc. I’m not especially well-versed in data visualization (yet) and I have about five minutes before my five month old is likely to wake up from a nap, so this leaves a lot to be desired – mainly, I need to go back and de-dupe the colors to better show which trend is which. Maybe I’ll come back to it in a future post. Still, in looking through the data and (properly) graphed trends, the stark reality of where we are a society – AI or not – remains. Small businesses hold more confidence than the medical system. People are more confident in large technology companies than Congress or the presidency.
You can find a link to a Google Sheets document that contains the data that I pulled here. It is not the complete set for all of the polling data, as it does not include the second page of dates for the entities that have data from earlier than 1995. It is important to note that this is one point of reference, not an exact representation of sentiment. That said…
Perhaps this is an area to be further explored. If generated content from AI truly does hold more trust than any of our societal institutions, we may need to completely rethink trust and confidence from the ground up – starting with our own minds.